
Les jeux modernes mettent l’accent sur les graphismes, et leur taille d’installation peut désormais dépasser 100 Go. Pour accéder à cette énorme quantité de données, la vitesse de traitement dépend des spécifications de la carte graphique (GPU) et, dans une certaine mesure, des autres composants de votre système.
Sur les cartes graphiques de la série GeForce RTX 40, NVIDIA a introduit de nouvelles innovations pour accélérer le processus, assurant des jeux fluides et des taux d’images plus rapides, évitant ainsi les problèmes de chargement de textures ou autres interruptions.
Le rôle important du cache
Les GPU sont équipés de caches mémoire à haute vitesse, situés près des cœurs de traitement du GPU. Ces caches stockent les données qui sont susceptibles d’être nécessaires. Lorsque le GPU peut récupérer les données à partir de ces caches plutôt que de les demander à la VRAM (mémoire vidéo, située plus loin) ou à la RAM système (encore plus éloignée), les données sont alors accessibles et traitées plus rapidement. Cela se traduit par une amélioration des performances, une fluidité de jeu accrue et une réduction de la consommation d’énergie.
Les cartes graphiques GeForce sont équipées d’un cache de niveau 1 (L1) dans chaque Streaming Multiprocessor (SM). Chaque GeForce RTX 40 Series Graphics Processing Cluster (GPC) peut contenir jusqu’à douze de ces SM. Ensuite, il y a un cache de niveau 2 (L2) plus grand et partagé, qui peut être rapidement accessible avec une latence minimale.

Chaque niveau de cache introduit une certaine latence, mais cela permet d’augmenter la capacité de stockage. Lors de la conception des cartes graphiques de la série GeForce RTX 40, NVIDIA a constaté que l’utilisation d’un seul grand cache L2 était plus rapide et plus efficace que d’autres alternatives, telles que des caches L2 plus petits associés à un cache L3 plus volumineux mais plus lent d’accès.
Lors de son fonctionnement, le GPU recherche d’abord les données dans le cache de niveau 1 (L1) situé dans le SM. Si les données sont trouvées dans le cache L1, il n’est pas nécessaire d’accéder au cache L2. Si les données ne sont pas trouvées dans le cache L1, cela s’appelle un « cache miss » et la recherche se poursuit dans le cache L2. Si les données sont trouvées dans le cache L2, cela s’appelle un « cache hit » L2, et les données sont transmises au cache L1, puis aux cœurs de traitement.
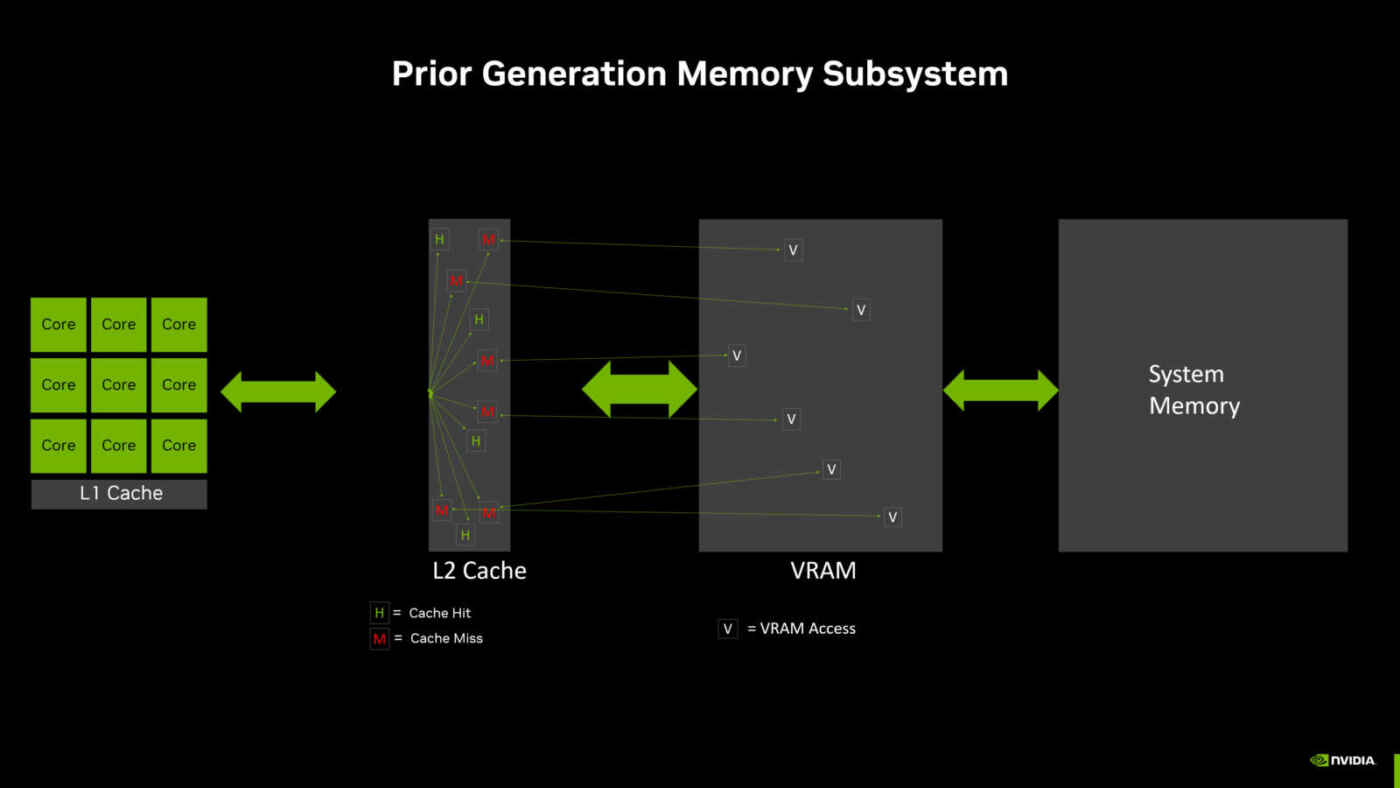
Si les données ne sont pas trouvées dans le cache L2, le GPU tente de les obtenir à partir de la VRAM. On peut observer plusieurs « cache misses » L2 dans le diagramme précédent, qui représente le sous-système mémoire de l’architecture précédente, et cela entraîne plusieurs accès à la VRAM.
Si les données ne sont pas présentes dans la VRAM, le GPU les demande à la mémoire du système. Si les données ne se trouvent pas non plus dans la mémoire du système, elles peuvent généralement être chargées depuis un dispositif de stockage comme un SSD ou un disque dur. Les données sont ensuite copiées dans la VRAM, le cache L2, le cache L1 et finalement transmises aux cœurs de traitement. Il est important de noter qu’il existe différentes stratégies matérielles et logicielles pour conserver les données les plus utiles et les plus réutilisées dans les caches.
Chaque opération supplémentaire de lecture ou d’écriture de données à travers la hiérarchie de mémoire ralentit les performances et consomme plus d’énergie. En augmentant le taux de réussite du cache, on améliore les taux d’images et l’efficacité.
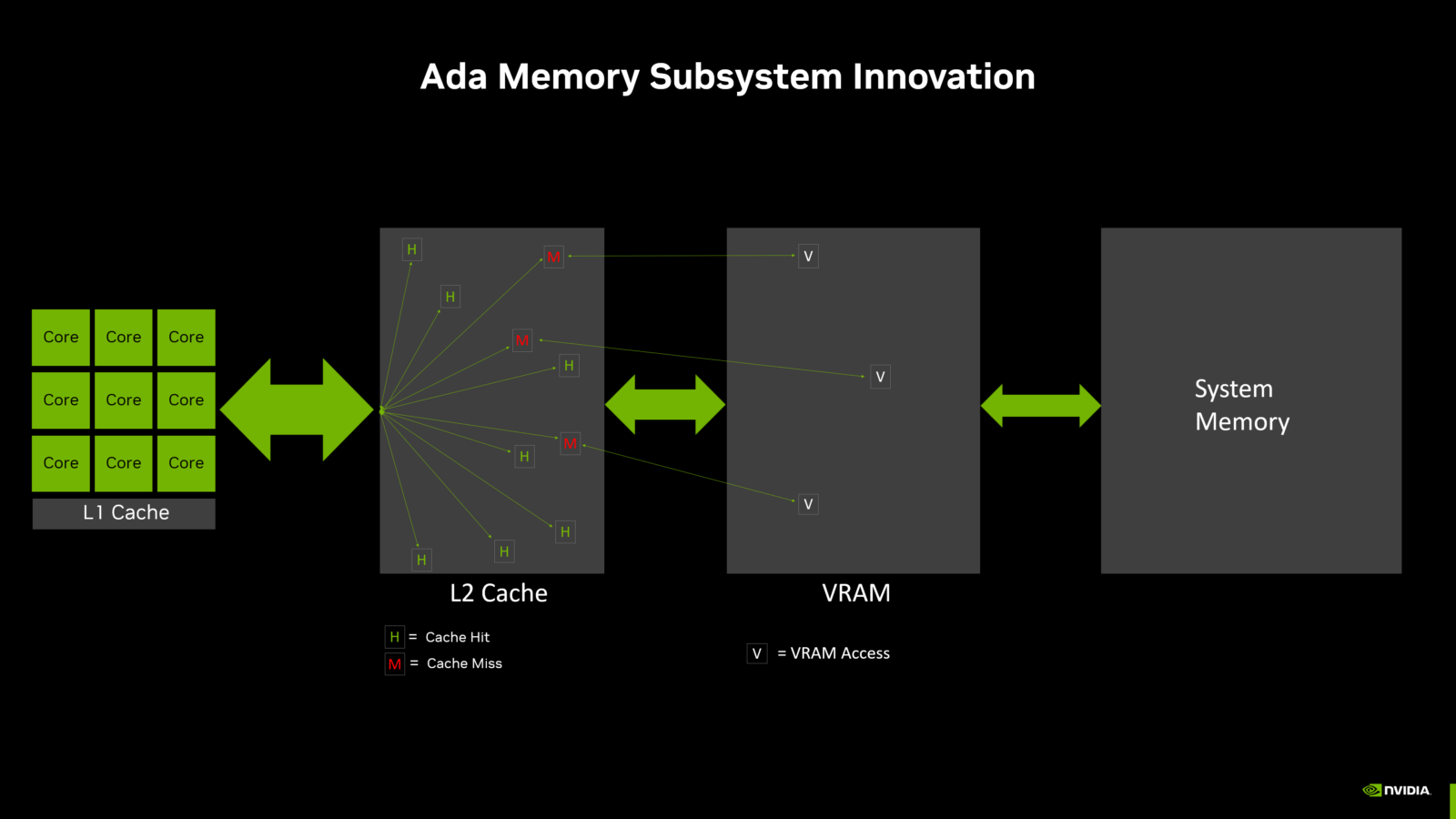
Comparé aux GPU des générations précédentes avec une interface mémoire de 128 bits, le sous-système mémoire de la nouvelle architecture NVIDIA Ada Lovelace augmente la taille du cache L2 de 16 fois, ce qui améliore grandement le taux de réussite du cache. Dans les exemples précédents, qui comparent des GPU Ada avec des GPU de génération précédente, le taux de réussite est beaucoup plus élevé avec Ada. Combinée à cette taille, la bande passante du cache L2 des GPU Ada a été augmentée par rapport aux GPU précédents. Cela permet de transférer plus de données entre les cœurs de traitement et le cache L2, le plus rapidement possible.
Comme le montre le diagramme ci-dessous, les ingénieurs de NVIDIA ont testé la RTX 4060 Ti avec son cache L2 de 32 Mo par rapport à une version de test spéciale de la RTX 4060 Ti utilisant seulement un cache L2 de 2 Mo, ce qui représente la taille du cache L2 des GPU de génération précédente avec une interface mémoire de 128 bits (où 512 Ko de cache L2 étaient associés à chaque contrôleur mémoire de 32 bits).
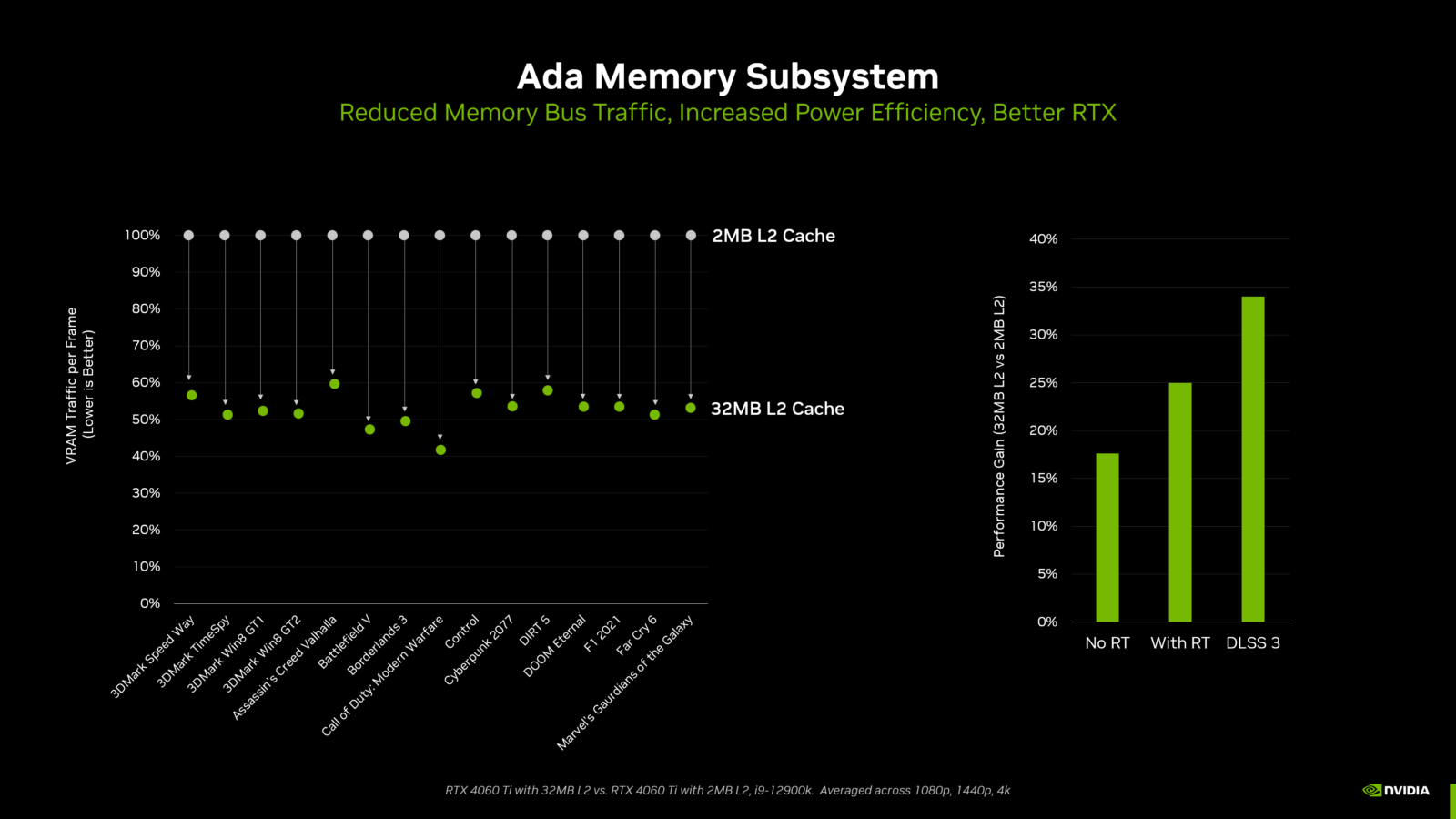
Lors des tests avec différents jeux et benchmarks synthétiques, le cache L2 de 32 Mo a réduit le trafic du bus mémoire de plus de 50 % en moyenne par rapport aux performances d’un cache L2 de 2 Mo. On peut observer une réduction des accès à la VRAM dans le diagramme du sous-système mémoire Ada ci-dessus.
Cette réduction de 50 % du trafic permet au GPU d’utiliser sa bande passante mémoire de manière 2 fois plus efficace. Ainsi, dans ce scénario, en isolant les performances mémoire, un GPU Ada avec une bande passante mémoire maximale de 288 Go/s aurait des performances similaires à celles d’un GPU Ampere avec une bande passante mémoire maximale de 554 Go/s. Dans une variété de jeux et de tests synthétiques, les taux de réussite du cache considérablement améliorés améliorent les taux d’images jusqu’à 34 %.
La largeur du bus mémoire est un aspect du sous-système mémoire
Traditionnellement, la largeur du bus mémoire a été utilisée comme une mesure importante pour déterminer la vitesse et la classe de performance d’un nouveau GPU. Cependant, la largeur du bus en elle-même ne suffit pas à indiquer les performances du sous-système mémoire. Il est donc utile de comprendre la conception globale du sous-système mémoire et son impact global sur les performances de jeu.
Grâce aux avancées de l’architecture Ada, notamment les nouveaux cœurs RT et Tensor, les vitesses d’horloge plus élevées, le nouveau moteur OFA et les capacités de DLSS 3 d’Ada, la GeForce RTX 4060 Ti est plus rapide que les cartes graphiques de génération précédente, à savoir la GeForce RTX 3060 Ti et la RTX 2060 SUPER, qui possédaient toutes deux un bus mémoire de 256 bits, le tout en consommant moins d’énergie.
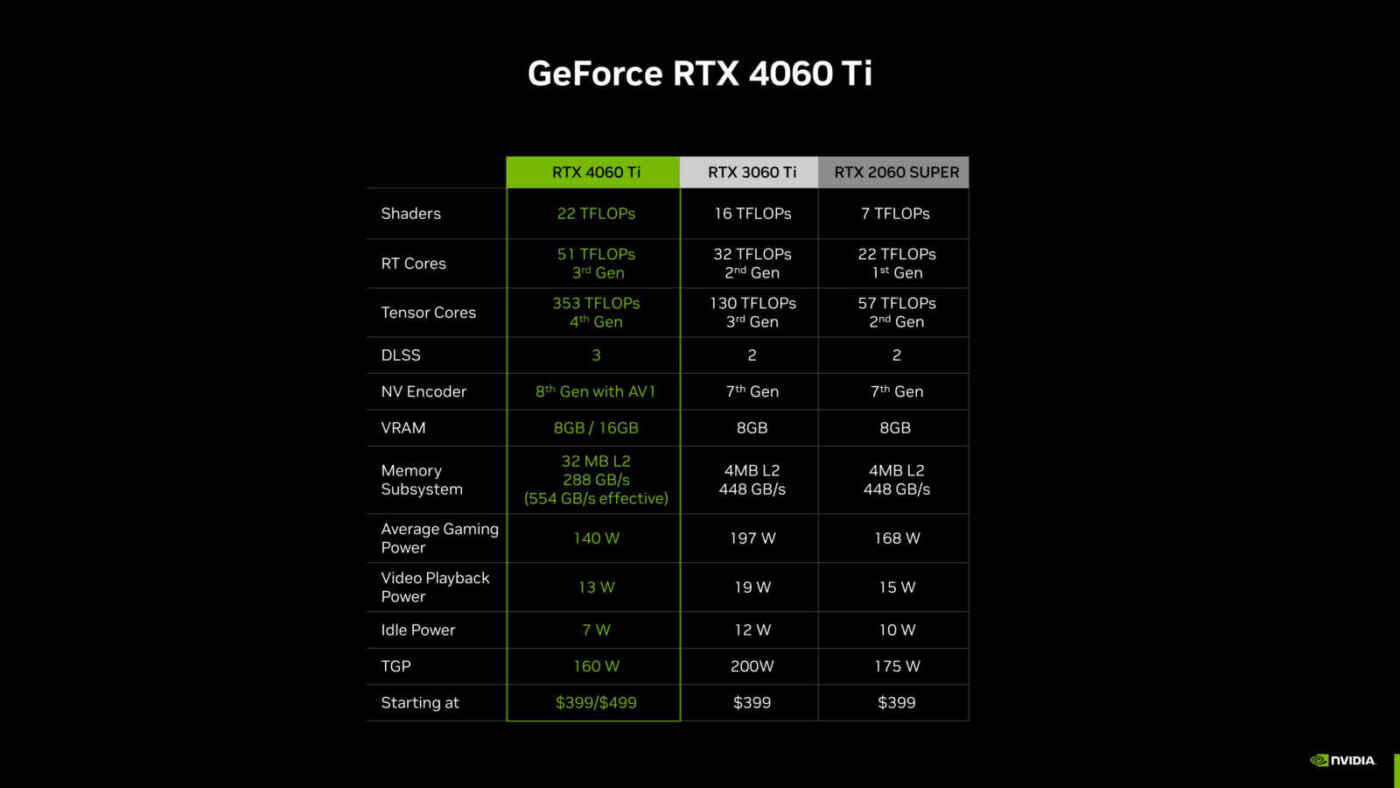
Il est important de noter que le gain de performances ne provient pas uniquement de l’augmentation de la largeur du bus mémoire, mais également des autres améliorations apportées à l’architecture et aux fonctionnalités du GPU. Ces améliorations globales du sous-système mémoire, combinées à d’autres caractéristiques clés de l’architecture Ada, permettent d’obtenir des performances supérieures et une meilleure efficacité énergétique.
En résumé, il ne faut pas se limiter à considérer uniquement la largeur du bus mémoire pour évaluer les performances d’une carte graphique. Il est important de prendre en compte l’ensemble du sous-système mémoire, ainsi que les autres fonctionnalités et améliorations apportées par l’architecture du GPU, afin de comprendre pleinement son impact sur les performances de jeu.
La quantité de VRAM dépend de l’architecture du GPU
Les quantités de VRAM sur les cartes graphiques sont déterminées par l’architecture du GPU. Les mémoires GDDR6X et GDDR6 de dernière génération sont disponibles avec des densités de 8 Gb (1 Go de données) et 16 Gb (2 Go de données) par puce. La capacité de chaque carte graphique dépend du nombre de puces mémoire utilisées et de la largeur du bus mémoire. Par exemple, sur les nouveaux GPU GeForce RTX 4060 Ti avec un bus mémoire de 128 bits, le modèle de 8 Go utilise quatre puces mémoire de 16 Gb, tandis que le modèle de 16 Go utilise huit puces de 16 Gb.
Il est important de noter que la capacité de VRAM ne dépend pas uniquement de la largeur du bus mémoire, mais aussi des choix de conception faits par le fabricant de la carte graphique en fonction des performances ciblées et du coût de production.
Certaines applications peuvent utiliser plus de VRAM
Au-delà des jeux, les cartes graphiques GeForce RTX peuvent être utilisées pour la conception 3D, le montage vidéo, le motion design, la photographie, la visualisation architecturale, les domaines scientifiques, le streaming et l’intelligence artificielle. Certaines des applications utilisées dans ces industries peuvent bénéficier de davantage de VRAM. Par exemple, lors de l’édition de vidéos en 4K ou 8K dans Premiere, ou de la création de scènes 3D complexes dans 3DSMAX.
Les outils d’affichage à l’écran (OSD) rapportent-ils précisément l’utilisation de la VRAM ?
Les testeurs citent souvent la métrique « utilisation de la VRAM » dans les outils de mesure des performances à l’écran. Cependant, ce chiffre n’est pas entièrement précis, car tous les jeux et moteurs de jeu fonctionnent différemment.
Dans la majorité des cas, un jeu alloue de la VRAM pour lui-même, en disant à votre système : « Je la veux au cas où j’en aurais besoin ». Mais le fait que la VRAM soit allouée ne signifie pas qu’elle est réellement utilisée dans son intégralité. En réalité, les jeux demanderont souvent plus de mémoire s’il y en a de disponible.
En raison du fonctionnement de la mémoire, il est impossible de savoir précisément ce qui est réellement utilisé à moins d’être le développeur du jeu avec accès aux outils de développement. Certains jeux proposent un aperçu de la quantité de VRAM nécessaire lors du réglages des options graphiques, mais même cela n’est pas toujours précis.
La quantité de VRAM réellement nécessaire variera en temps réel en fonction de la scène et de ce que le joueur voit.
De plus, le comportement des jeux peut varier lorsque la VRAM est réellement utilisée au maximum. Dans certains jeux, la mémoire est purgée, ce qui entraîne une baisse notable des performances pendant que la scène actuelle est rechargée en mémoire. Dans d’autres jeux, seules certaines données seront chargées et déchargées, sans impact visible. Et dans certains cas, les nouveaux éléments peuvent être chargés plus lentement car ils sont désormais extraits de la mémoire système.
Pour les joueurs, la seule façon de vraiment comprendre le comportement d’un jeu est de jouer. Les joueurs peuvent consulter les mesures de la fréquence d’images « 1% low« , qui peuvent aider à analyser l’expérience de jeu réelle. La métrique « 1% basse » – présente dans la superposition de performance et les journaux de l’application NVIDIA FrameView, ainsi que dans d’autres outils de mesure – mesure la moyenne des 1% de générations d’images les plus lents sur un laps de temps. Si le chiffre est trop élevé, l’expérience visuelle n’est pas optimale.



